Stop being the brain, become the body
· 8 min read
GymLogic is a workout app, built on the side as a solo project. This is the build log of an architecture pivot, with a couple of real conversation screenshots further down so you can see what the bet bought.
Most “AI apps” shipping in 2026 are thin wrappers: an LLM behind a UI, sometimes dressed up as magic, sometimes as a polished if-else tree. The agentic shift inverts that. Your product becomes the thing agents call, not the thing that calls an LLM on the user’s behalf. I shipped the wrapper version of GymLogic too. Then I flipped it. The user’s own agent calls my server now. The product is the body: data, catalog, guardrails, persistence. The agent is the brain. I brought my own everything; I now bring almost nothing.
This post is why I did it, what I deleted to ship it, and the moment I almost rebuilt the wrapper I was trying to escape.
I was the black box too
The first version of GymLogic’s “AI features” looked like every other AI app. The React UI sent a structured prompt to a Supabase Edge Function. The function bundled the user’s profile, recent training history, and a slice of the catalog. Gemini 2.5 Flash returned a generated workout, parsed and validated against a schema. The UI rendered it. The user never saw the model, never picked it, and couldn’t bring their own.
The catalog (360+ exercises, fully tagged) was locked behind in-app search. The progression logic (RIR-based set adjustment, Epley 1RM, volume-by-muscle-group analytics) lived in file:src/lib/, reachable only through a React component tree. Every generation cost a Gemini call, and every model swap meant re-tuning a prompt the user couldn’t read.
It worked. It was also, in retrospect, the meme.
BYOA, briefly
MCP (the Model Context Protocol) is an open spec from Anthropic that lets an LLM agent discover and call your tools over HTTP, with OAuth-scoped access and a JSON-RPC payload. The transport is boring on purpose. The interesting part is what it implies architecturally: your product stops being an LLM caller and becomes an LLM callee. Claude Desktop, Cursor, Le Chat, Gemini CLI all speak it.
BYOA, or Bring Your Own Agent, is the consequence, and the architecture under most actually-agentic AI products. Users connect their agent (the one that already knows their calendar, their email, their codebase, their life) to your server. They authenticate via OAuth. They ask their agent something. The agent decides which of your tools to call, in what order. You expose data, schemas, and guardrails. You no longer pick the model or write the prompt. The user’s agent provider pays for inference.
The line that crystallized this for me, written in the epic brief and never edited since:
Stop being the brain. Become the body.
What that looks like
A real conversation against mcp.gymlogic.me, run from Claude Desktop with two months of training data behind it. No prompt engineering on the GymLogic side; the agent picked which tools to call, asked its own clarifying questions, and figured out the rest.
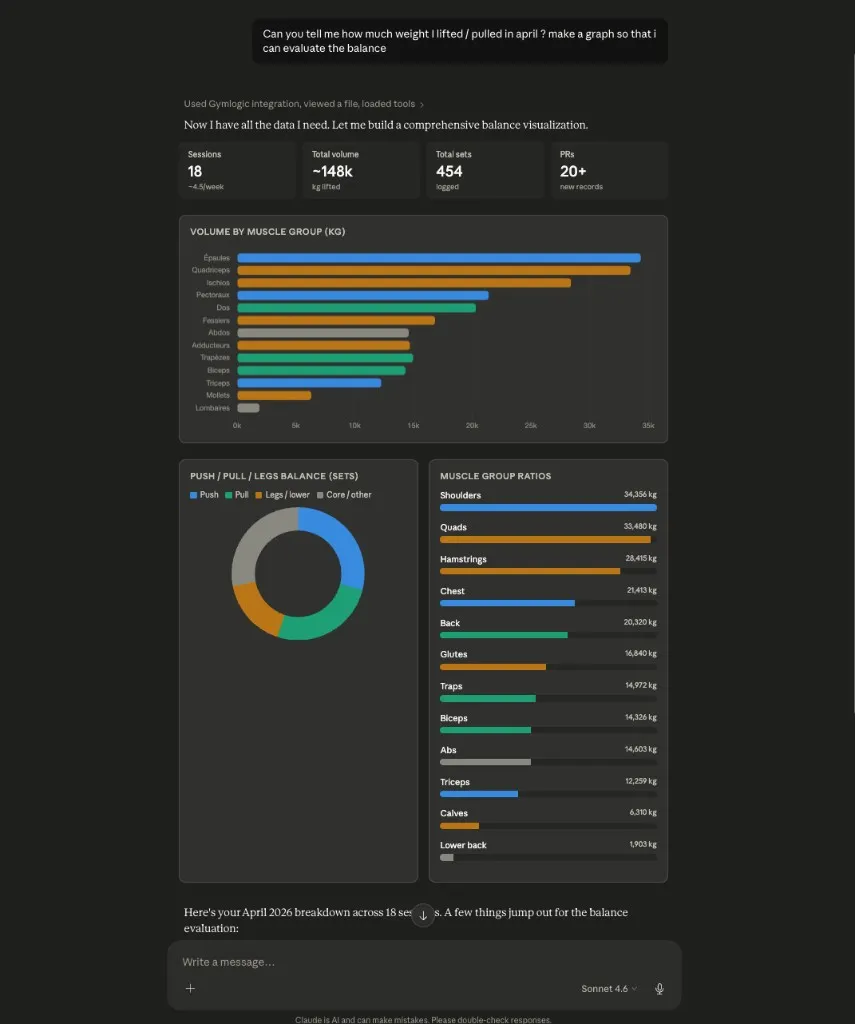
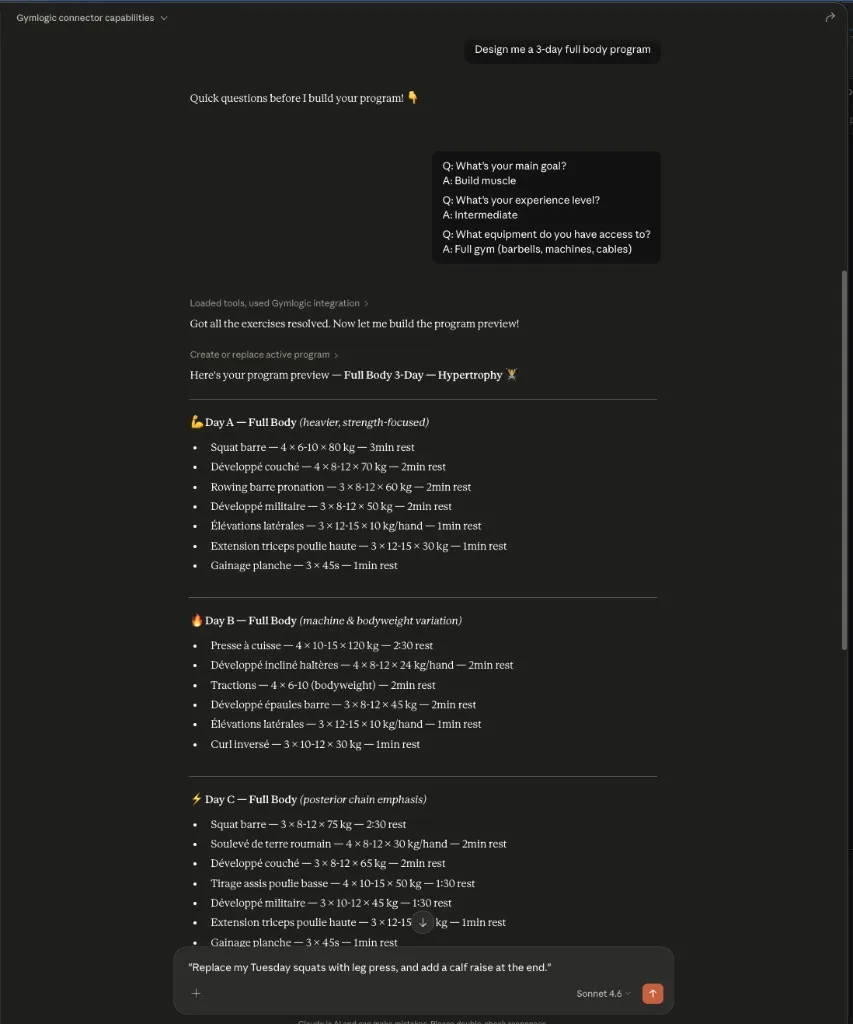
The split is the point. The body did its job: returned structured, RLS-scoped data through ten MCP tools and one resource, validated the catalog, persisted the writes. The brain (Claude in this run, Le Chat in another) reasoned across the conversation, asked clarifying questions, and made every call.
If you build software, the meaningful detail is which tools the agent chose unprompted and which ones it ignored. If you train, the meaningful detail is that 148k kg is real data — and the program ends up in your account afterward, in the same programs and workout_days rows the React app would have created.
What I deleted to ship it
The plan, originally, was Hono for HTTP, the MCP TypeScript SDK for protocol handling, and Zod for tool input validation. Three frameworks. Standard 2026 stack. I shipped none of them.
Hono went first. The MCP function only handles three HTTP methods: POST for JSON-RPC, OPTIONS for CORS, DELETE for session close. A full HTTP framework added cold-start weight for routing logic that fits in 30 lines of plain Deno.serve.
@modelcontextprotocol/sdk went next. The SDK’s McpServer plus its Streamable HTTP transport pulled heavyweight dependencies into Edge Function bundles for what is, beneath the abstractions, a thin JSON-RPC dispatcher. I replaced it with a ~120-line handleRpc switch that routes initialize, tools/list, tools/call, resources/list, resources/read directly. Tool registration became plain objects with handler functions in file:supabase/functions/mcp/tools/registry.ts.
Zod followed. Without the SDK there was no registerTool() expecting Zod schemas. Tool inputSchema is declared as plain JSON Schema, sufficient for MCP client introspection and lighter at runtime.
The end state is a Supabase Edge Function with zero npm dependencies. The only import is esm.sh/@supabase/supabase-js@2, consistent with the other Edge Functions in the codebase. This isn’t a “frameworks are bad” argument. The honest read is narrower: MCP turned out to be small enough that the frameworks were taxing me for routing logic I didn’t have. If your MCP server has dozens of tools, the math may flip; mine doesn’t.
I almost rebuilt the wrapper, in MCP costume
The first tech plan, before the rewrite, scoped four “Phase 2” tools: suggest_progression, calculate_1rm, validate_workout_plan, get_muscle_balance_report. Each one wrapped a piece of in-app domain logic and re-exposed it as an MCP tool. The pitch sounded right at the time. Coaching expertise, available to the agent, powered by my science.
It was the wrapper, in MCP costume.
A suggest_progression tool encodes my opinion about how the user should progress — the same opinion that previously lived inside a Gemini prompt. The agent now calls my cached opinion instead of reasoning from data. The medium changed; the closed loop didn’t.
The Phase 2/3 tech plan re-scoped the work. The line I kept verbatim:
Expertise lives in the agent, not in a suite of MCP coaching micro-tools.
The deferred list is still on disk in file:docs/done/Tech_Plan_—_MCP-First_Architecture_#231_Phase_2_and_3.md. Nothing about the rejection was a flash of insight; I drafted it, read it back, and recognized my own handwriting in what I was supposedly leaving behind. The harder lesson is that BYOA is a daily decision, not a one-time architecture pick: every new MCP tool gets the same test, asking whether it exposes data and guardrails or bakes in cached reasoning. The first kind compounds. The second kind is the same coupling I just paid to escape, dressed up.
”But what about quality?”
The strongest pushback on BYOA comes from the closed-loop defender, and it’s not stupid. You give up polish. There’s no optimizing for a single agent (you don’t know which one the user brought) and no pinning a model tuned for your use case. Vertical integration wins on quality when product polish matters, the argument goes.
It’s right, on its time horizon. It’s also more right when you can afford it.
A closed loop done well (pinned model, tuned prompts, shaped outputs, regression evals) is real data-science work. This is a side project shipped in weeks, on evenings, with a budget of zero. Even if vertical integration were the strategically better bet here, I couldn’t run it. BYOA isn’t just a different bet for me; it’s the only one a solo dev can maintain. Probably true for most of the indie “AI apps” you see in 2026: wrappers, not because their builders are wrong about strategy, but because the alternative needs a team they don’t have.
The disagreement, for builders who have the option, is which bet to make. A closed loop bets that one model wins: yours, picked once, optimized around, never swapped. BYOA bets the model layer commodifies, that “which AI we use” becomes as boring as “which CDN we use”.
If you’ve watched the last three model upgrades quietly break your “optimized prompt”, you already half-agree. The quality advantage of a tuned closed loop shrinks every six weeks; the data and guardrails advantage compounds.
What’s next
Live at mcp.gymlogic.me/functions/v1/mcp if you want to point your own agent at it.
The next post is the gory technical autopsy: what’s in those 120 lines of JSON-RPC, how OAuth 2.1 lands under MCP, and what I’d cut differently if I did it again. This one was about the bet.
Stop being the brain. Become the body.